Ce document présente une méthodologie de mise en oeuvre de la supervision.
Objectifs de la supervision
Les acteurs et les rôles
La supervision et les CNS
Les éléments supervisés
Nagios : Architecture technique et applicative
Nagios : Les outils de la supervision
I. Objectifs de la supervision
1. Améliorer les CNS
Les CNS (Contrats de Niveau de Service aussi appelés SLA - Service Level Agreement) garantissent la qualité des services fonctionnels de l'entreprise.
La mise en place d'un outil de supervision doit optimiser la gestion des CNS.
Les interactions entre CNS et supervision sont décrites dans les chapitres suivants.
2. Fournir un outil de supervision pour chaque entité
Chaque entité d'une DSI a ses propres objectifs. La mise en place de la supervision doit répondre aux besoins de chacun.
Les acteurs et les outils sont décrits dans les chapitres suivants.
3. S'intégrer avec la gestion des incidents (ITIL)
La supervision doit être liée aux processus de gestion des incidents.
Ce lien s'applique notamment sur deux points :
- génération automique d'incident pour les alertes critiques fonctionnelles remontées par l'outil de supervision,
- liaison direct avec la "knowledge base" de la gestion des incident.
Des exemples d'implémentation de ces liens sont décrits dans les chapitres suivants.
II. Les acteurs et les rôles
L'entité de support téléphonique (support niveau 1) doit avoir une vue macro de l'état des services fonctionnels : cartographie des services rendus. Elle permet de communiquer aux utilisateurs avec le maximum d'informations et de donner une vision clair. L'entité peut aussi remonter les problèmes au support niveau 2.
L'entité d'administration technique (support niveau 2) doit avoir une vue détaillée de l'ensemble des services techniques et applicatifs.
Elle peut ainsi :
- appliquer un mode préventif au suivi de l'infrastructure,
- appliquer les corrections connues (knowledge base) en cas d'incident,
- qualifier et transférer l'incident au support niveau 3 adequat.
De plus, cette entité a pour rôle l'administration fonctionnelle de l'outil de supervision (ajout / suppression de checks, mise en place de downtime, configuration des notifications, ...).
L'entité de support niveau 3 technique (architectes techniques / experts techniques) doit avoir une vue détaillée et historisée de l'ensemble des services techniques afin d'aider à résoudre les incidents.
L'entité de support niveau 3 applicatif (architectes applicatifs / développeurs experts / référent de société éditrice) doit avoir une vue détaillée et historisée de l'ensemble des services applicatifs afin d'aider à résoudre les incidents.
Cela peut s'inscrire dans l'application des processus ITIL au sein d'une DSI (définition des rôles).
III. La supervision et les CNS
la supervision des services fonctionnels permet de rendre des services pour les CNS.
Trois éléments importants qui forment un CNS sont les délais de réaction en cas d'incident, les délais de rétablissement de service et les taux de disponibilité des services.
La mise en place d'une infrastructure de supervision et de procédures de qualité sur les services fonctionnels ont un rôle important dans l'établissement et le respect de ces CNS.
Elles permettent de :
- prevenir certains incidents par des systèmes de suivi d'indicateurs clefs et des alertes préventives bien qualibrées,
- optimiser la détection des incidents par un système d'alerte optimisé,
- optimiser les résolutions d'incidents par la mise en place de procédures optimisées et en amélioration continue.
De plus, les bilans fournis par l'outil de supervision sur l'état des services permettent de valider ou d'invalider une CNS (voir chapitre sur les outils de la supervision).
IV. Les éléments supervisés
Les éléments supervisé peuvent être regroupés en différentes familles. Ces familles se définissent par la nature de l'élément supervisé et par l'objectif de cette supervision.
Les principales familles d'éléments sont :
- les éléments hardware (température CPU - alimentation - disques, vitesse des ventilateurs, état des interfaces pour les switchs, ...),
- les éléments système (réseau, load, I/O, charge CPU, utilisation RAM, entropy, OS, ...),
- les éléments applicatifs (service web, service ldap, service messagerie, service d'impression, ...),
- les éléments fonctionnels (applications du SI).
Un check est défini par le script correspondant, les seuils et les valeurs de performance.
Les seuils sont les valeurs correspondantes aux retours du check.
Dans Nagios, 2 seuils sont donc défini : le seuil warning et le seuil critical.
Lorsque la valeur de l'élément checké par le script est supérieure au seuil critical, le script remonte en CRITICAL (exit 2).
Lorsque cette valeur est supérieure au seuil warning mais inférieure au seuil critical, le script remonte en WARNING (exit 1).
Lorsque cette valeur est inférieure au seuil warning, le script remonte en OK (exit 0).
Les valeurs de performance sont retournées par le script et peuvent être utilisées pour construire les graphs RRD.
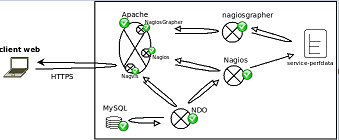
V. Nagios : Architecture technique et applicative
L'outil Nagios répond à ces critères et permet de mettre en place une supervision qui s'intègre aux processus du SI.
L'architecture du composant est présentée dans le schéma suivant :
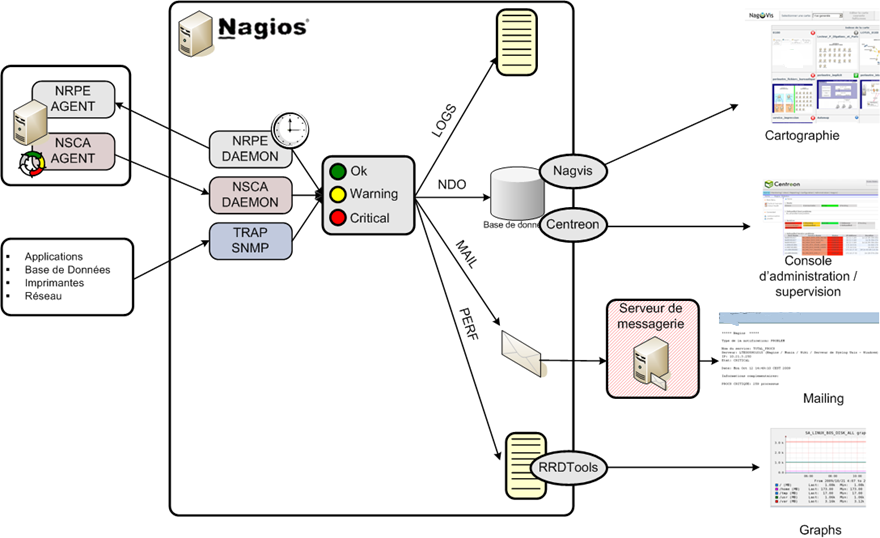
En amont, la supervision est réalisée de différentes manières :
- déploiement d'un agent (agent NRPE) sur les serveurs qui communique avec Nagios et déclenche à la demande de Nagios des checks locaux et transmet les résultats,
- le déploiement d'un agent (agent NSCA) sur les serveurs qui déclenche de lui même des checks locaux et transmet les résultats le cas échéant (ex. : sur modification d'état),
- le serveur Nagios est à l'écoute de communication SNMP pouvant être déclenchées par certains composants actifs du SI (ex. : BD, imprimantes, composants réseau, ...),
- le serveur Nagios peut déclencher des checks distants par le biais du serveur SSH (nécessité de mettre en place un user nagios avec connexion sur présentation de certificat SSL).
En aval, le serveur Nagios analyse les remontées des checks et alimente différents moyens de communication (suivant configuration) :
- écriture dans des fichiers de log locaux,
- écriture dans une base NDO,
- envoi de mail,
- déclencher des scripts spécifiques (ex. : interaction avec l'outil de gestion des incidents),
- génération de graphs RRD.
La base NDO est ensuite utilisée comme source de données pour des interfaces web de visualisation des checks (ex. : Nagios, Centreon) et des interfaces web de visualisation de cartographies (ex. : Nagvis).
Les graphs RRD sont utilisés comme source de données pour des interfaces web de visualisation (ex. : Nagiosgrapher, Centreon, PNP).
VI. Nagios : Les outils de la supervision
1. Interface web de suivi et d'administration
L'application Nagios fournit une interface web de suivi et d'administration.
Elle permet principalement de visualiser les serveurs et checks et de sélectionner les checks en erreurs.
Voici un exemple de quelques checks pour un serveur donné :

Pour chaque check (chaque ligne), on a :
- nom du check (lien HTTP vers la page web de détails du check),
- lien HTTP vers le référentiel des checks,
- miniature du graph rrd de performance en lien HTTP vers le graph détaillé,
- état du check (OK / WARNING / CRITICAL),
- date de dernier check,
- durée de l'état courant du check,
- nombre de checks en mode soft (voir chapitre sur les mails et notifications),
- information sur le retour du check.
La page de description détaillée du check est la suivante :
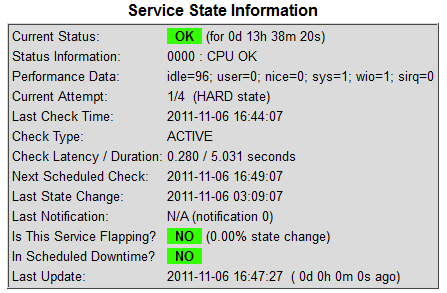
Les principales informations sont :
- les dernières valeurs de performance,
- le statut du check a t'il changé plusieurs fois dernièrement (flapping).
2. Mails et notifications
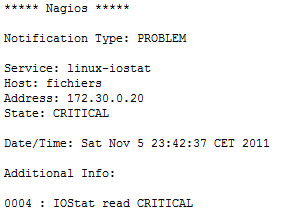
L'outil Nagios permet l'envoi d'alerte (notamment mail et sms) lors de changement d'état d'un service. Ceci est appelé les notifications.
Les notifications sont configurables de manière à ce que les alertes ne soient pas envoyées dès le changement d'état. Ainsi, un check passe en "soft state" dès changement d'état et est re checké plus rapidement plusieurs fois avant de passer en "hard state" et de déclencher les notifications. Cela permet de ne pas flooder de mail les administrateurs.
Voici un exemple de mail de notification :
3. Performances
Les données de performance fournies par les checks permettent à l'outil Nagiosgrapher d'établir des graphs sur le temps.
Voici un exemple de graph :
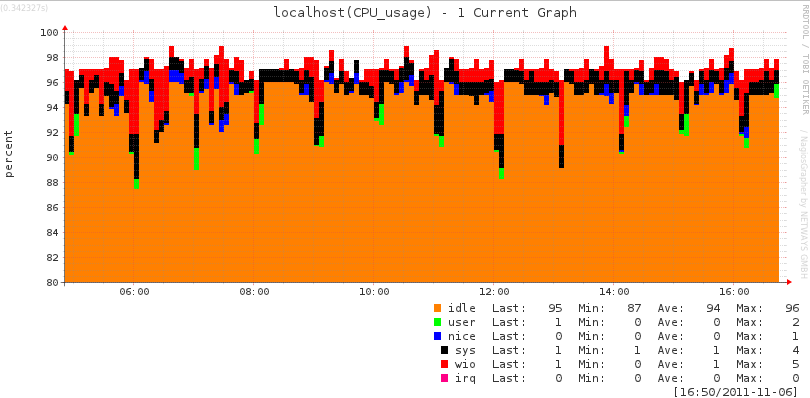
Les données de performance permettent d'améliorer la qualification des seuils et le diagnostic en cas d'incident.
4. Statistiques
Pour chaque check, il est possible de visualiser le diagramme d'état dans l'interface web de Nagios.
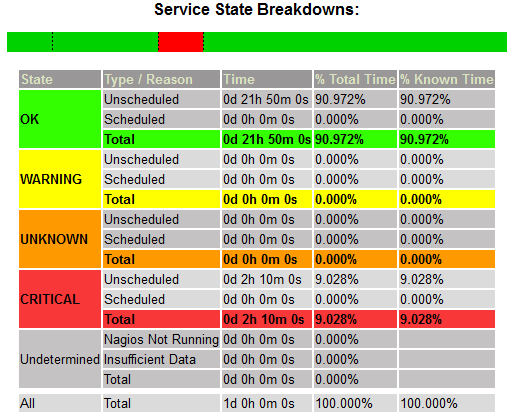
Ces statistiques sont particulièrement utiles pour les services fonctionnels sur lesquels un CNS est défini. Elles permettent de s'assurer que les contrats sont bien respectés au fil du temps.
5. Référentiel des checks (knowledge base)
Le référentiel des checks permet de décrire les checks et d'établir une "knowledge base" sur les incidents.
L'utilisation d'un wiki permet l'amélioration continue de cette base.
Voici un exemple de fiche de check :
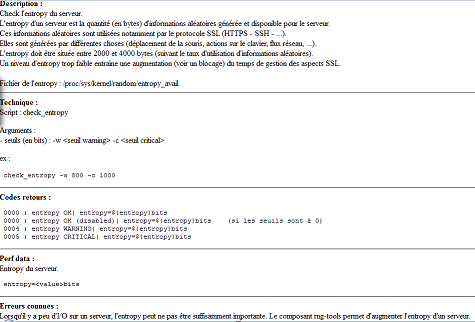
Il est alors possible d'intégrer des liens vers ces fiches dans l'interface de Nagios. Le lien "wiki" ci-dessous en est un exemple :

6. Cartographie
Les cartographies permettent de fournir une vue synthétique et fonctionnelle de la supervision. Elles fournissent une vue fonctionnelle globale pour l'entité de support niveau 1, elles fournissent une vue applicative et technique détaillée afin d'aider au diagnostic.
Voici quelques exemples de cartographies :
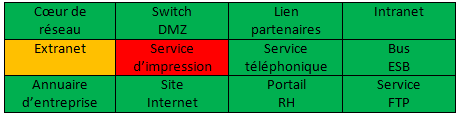

7. Pilotage 7x7 - 24x24
La plateforme Nagios peut être couplée avec un modem GSM enfin d'envoyer des SMS en cas de problème.
Une autre solution est de posséder un smartphone de nouvelle génération permettant de faire des requêtes régulières au site web Nagios. Pour ce faire, l'interface web d'administration de Nagios doit être accessible de l'extérieur de l'entreprise (il est alors nécessaire de mettre en place une sécurité HTTPS et authentification digest).
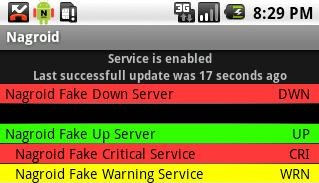
Par exemple, l'outil Nagroid sur Android permet d'être alerté en cas de problème (sonnerie / vibration / interface). De plus, cet outil permet de visualiser les problèmes en cours. Il n'est pas encore possible d'effectuer des actes d'administration depuis cette interface.
Voici un exemple de l'interface Nagroid :
8. Lien avec la gestion des incidents (ITIL)
Il est possible dans Nagios de déclencher des scripts au changement de statut de checks. Un script faisant des requêtes HTTP ou web service peut ainsi générer un incident dans l'outil de gestion des incidents.
La supervision s'intègre alors complètement dans la mise en place des processus ITIL.
Les checks sont alors reliés aux CI définis dans la CMDB de l'entreprise.